
Think about your objective, understand data requirements, select the right big data tools, and more
This is the second article of our Big Data series. You can read the first one here:
Big Data in the Cloud: Why Cloud Computing is the Answer to Your Big Data Initiatives
To get notified of our future Big Data in the Cloud posts, click here to sign up for our email list.
In today’s business landscape, data is the new oil – the most important resource that has the power to transform every industry.
Organizations that haven’t taken advantage of the data they are collecting are being left behind. Therefore, it’s no surprise that so many companies are eager to jump on the big data analytics train.
Given the sheer enormity of big data – and the certainty that it’s only going to get bigger – businesses are looking to the cloud for their big data needs. The cloud provides various benefits, including scalability, flexibility, and cost savings, that can help organizations of all sizes take advantage of their big data.
Yet the move to the cloud for big data purposes can be a daunting one. Having a plan and strategy is critical, and it’s important to take a methodical approach to your big data cloud migration.
In this post, we’ll discuss eight key steps you should consider to ensure a seamless journey to the cloud to achieve your big data goals.

1) Identify your primary objective
Starting a big data project solely for the purpose of exploring possibilities, without a clear objective, is a huge waste of time, effort, and resources.
Many enterprises have learned this lesson the hard way. As such, 85% of big data projects fail. That’s insane.
This high failure rate has little to do with the technology itself. Rather, organizations often don’t have a clear vision of the insights they want to extract from their data and how it impacts their businesses.
To increase your likelihood of success, you need to identify the key goals and objectives you’d like to achieve from your big data projects. Some questions to ask include:
- What are the overarching goals you would like to achieve by better analyzing your data?
- How do these goals fit with your overall business strategy?
- Which business units will be most impacted?
- What does a successful big data implementation look like?
It’s imperative to establish a definition for project success upfront so everyone knows what to work towards.
Once you clarify your objectives, you can dig into the details of your big data implementation.
2) Understand your data storage infrastructure needs
The next step is to understand your data and the database infrastructure required to store and analyze it.
Your analysis should include the following factors:
- The type of data you will be storing and analyzing
- How much data you will need to deal with
- How quickly you need analytical results
SQL vs. NoSQL Databases
If the type of data that you’re storing and analyzing is primarily well-organized and structured, a SQL (structured query language) database is likely the best option.
SQL databases are perfect for relational data, such as accounting data, client information, retail inventory data, and other types that can be neatly organized into rows and columns.
SQL database offerings include MySQL, Microsoft SQL server, PostgreSQL, Oracle, and many others. Of course, the major cloud computing providers have cloud versions of SQL databases. AWS has RDS and Aurora, Azure has SQL Database, and Google Cloud Platform (GCP) has Cloud SQL.
However, the rise of big data and the widespread adoption of distributed computing has paved the way for a more flexible database technology: NoSQL (Not only SQL).
While SQL works for data that conforms to relational schemas, NoSQL is much more flexible and is applicable for other types of unstructured data such as social media, sensor, and other forms of human- and machine-generated data.
NoSQL is better at processing and storing data in real time and scales horizontally, which makes it ideal for ingesting and managing massive volumes of data.
NoSQL database options include MongoDB, Redis, Cassandra, and many others. Cloud options include Amazon DynamoDB, Azure CosmosDB, and Google Cloud Bigtable.
So, does this make NoSQL better for big data analytics? Not exactly. By definition, big data encompasses structured and unstructured data, and both have the potential to reveal significant insights. The choice of whether to use a SQL or NoSQL database depends on your particular situation.

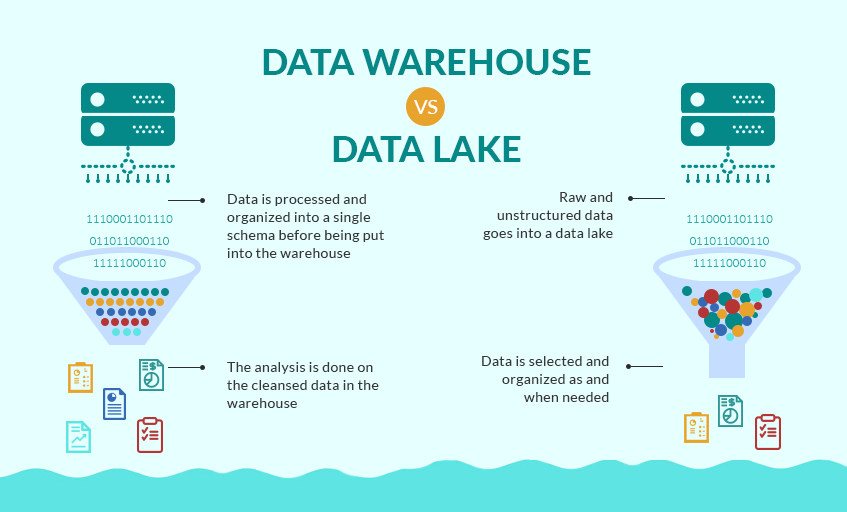
Data Lakes and Warehouses
Other infrastructure considerations include whether you will need a data lake or data warehouse.
A data lake is a central repository that can store structured or unstructured data as-is, without any kind of processing or modeling. The data stored can be in its rawest form and you can take a “store everything” approach with a data lake. Amazon S3 and Glacier, Azure Data Lake Storage, and Google Cloud Storage are often used as the foundation of data lakes.
Data warehouses are central data repositories that integrate data from multiple sources, such as databases, transactional systems, data lakes, and other sources. This data needs to be processed and normalized so you can easily and quickly run reports. Cloud data warehouse options include Amazon Redshift, Azure SQL Data Warehouse, and Google Cloud BigQuery.
One of our software developers, Robert Chen, came up with this analogy – a data lake would be your kitchen pantry and fridge, where you store all types of food, and a data warehouse is your kitchen countertop where you bring together the ingredients you need to make dinner. Pretty good!
Data storage infrastructure is a huge topic that we’ll dig deeper into in future posts.
3) Find the right big data tools for your analytics needs
Once you’ve done a thorough assessment of how your data should be stored and managed, it’s time to decide on the tools that will let you best extract analytical insights from your data.
We’ll definitely write more about big data tools in future posts, but here is an overview of some of the more common tools for various uses.
Distributed data storage and processing
Because of the “bigness” of your data, a distributed data processing tool may be necessary to efficiently manage and process all of your data.
Hadoop and Spark have emerged as two of the most commonly used open source tools that allow for distributed processing of large data sets.
Hadoop, through its various modules, splits big data and distributes this across numerous nodes in a cluster so data can be processed in parallel. Spark specializes in real-time, in-memory processing using a concept known as Resilient Distributed Dataset (RDD), and hence is faster than Hadoop. However, it doesn’t perform distributed storage like Hadoop does. Hadoop and Spark can certainly work together to achieve the speed and efficiency you need.
These tools can be installed on premise, but are ideal for deploying in cloud environments. The top cloud providers all have service offerings that can run Hadoop or Spark clusters. AWS has Elastic MapReduce, Azure has HDInsight and DataBricks, and Google Cloud offers Cloud Dataproc.
Real-time data monitoring and feedback
Real-time data monitoring and analysis can help facilitate decision making on the fly.
When combined with immediate alerts, real-time data analysis can help your business make quick operational decisions that can improve customer satisfaction.
Use cases of real-time data analysis include detection of credit card fraud, recognition of healthcare emergencies, identification of software system failure, and many more.
Some of the top streaming analytics platforms that can be used for real-time data analysis include Amazon Kinesis, Azure Stream Analytics, Google Cloud Stream Analytics, and Apache Storm. These are all designed to gather and analyze real-time data from and in the cloud, making them ideal applications to form the foundation of your real-time data analysis pipeline.

Creation of reports and dashboards
Graphs and visualizations make it easy for analysts and decision makers to assess information at a glance. That’s why data visualization tools are such an important part of the analytics stack.
Whether you opt for cloud-based tools, rely on the established providers, or go for the smaller players who specialize for certain industries, there’s no shortage of data visualization tools on the market.
Tableau is one of the most popular options, as is Domo, Qlik, and others. Amazon offers QuickSight, Azure has Power BI, and GCP provides various tools like Data Studio that you can link to BigQuery to power your business intelligence dashboards.
4) Understand your security and compliance requirements
The more data you have, the more valuable insights you can extract. But you also have to be more careful about protecting the security and privacy of all of this data.
It’s no secret that data breaches can lead to serious ramifications. Putting your customers’ personally identifiable information at risk can lead to financial loss, regulatory sanctions, and reputational damage. So while you want to find value in big data, you can’t do so at the expense of security and privacy.
Big data has unique security requirements because of its volume and variety (massive, structured and unstructured data), dispersed storage (on-premise or cloud), distributed processing (across multiple cluster nodes), and varied infrastructure and analytics tools. Plus, when your data is in the cloud, you will have to work closely with your cloud services provider to negotiate strong security SLAs.
There is no one-size-fits-all solution when it comes to big data security. IT security professionals recommend a blend of tactics customized for your big data platform. Some of the technologies and tools that could go into your big data security solution would include:
- Encryption tools that work with different types of data and storage formats
- A centralized key management system that encompasses the equipment, policies, and processes regarding handling of keys
- Strict user access control policies
- Systems for intrusion detection and prevention
Such techniques are not only critical for mitigating security risk, but also for complying with the ever-tightening regulation standards. For example, if you are using data of EU residents, then you should ensure that your processes for collecting, storing, processing, and analyzing such data are in compliance with the recently-enacted GDPR. This would mean that even the location of your data center could become an issue, in which case, using a private or hybrid cloud model would be best for your company (more about cloud models in the following section).
Despite the absence of industry-wide standards for securing big data, organizations should still put security as a primary consideration at every step of data handling. The key is to get all the the people in your organization – management, data team, and IT security team – to view data security as a common goal that requires concerted effort to achieve.
5) Choose the best cloud model for your situation
One of the key decisions you’ll have to make when moving your data to the cloud is whether to use a public, private, or hybrid cloud model.
You’ll need to balance cost, technical efficiency, and security and compliance requirements before making a decision. Below is a quick overview of each cloud model. If you want to read more detail about the pros and cons of each, click here.
Public cloud
In a public cloud, there is ‘sharing’ of physical hardware among organizations, while the entire cloud infrastructure is owned and operated by a third-party cloud service provider like Amazon, Microsoft, or Google. The public cloud’s biggest advantage is its ability to infinitely scale infrastructure resources at a moment’s notice without the need for upfront investment, which will be very helpful as the amount of your data grows. In addition, using public cloud services allows you to take advantage of the newest cutting-edge technologies for your analytics initiatives.
Private cloud
If you need a more customized setup and maximum control over your data, a private cloud might be the best option for your big data initiative.
In this model, your data resides in a cloud environment but the infrastructure used is not shared by multiple organizations; it’s fully dedicated to your company. Private clouds can either be maintained on-premise or in a third-party data center.
With a private cloud, you have full knowledge and control over the security practices and data management principles that are being used. This would be advantageous for security and compliance purposes, but comes at a steeper cost and more management overhead.
Hybrid cloud
Businesses looking for an option that will give them the best of both worlds in terms of customizability, scalability, security, and cost-efficiency can opt for a hybrid cloud environment.
A hybrid cloud combines a public and private cloud, both of which operate independently but communicate through orchestration. You can customize your hybrid cloud implementation to fit your needs.
An example use case would be storing confidential data within your private cloud while running analytical queries on less-sensitive data through a public cloud service.
While hybrid clouds certainly provide many benefits, they require a higher level of technical management and orchestration.

6) Evaluate the cloud providers offering big data services
After you’ve performed steps 1-5, you should have a solid idea of everything you need to get your cloud big data initiative going. Now it’s time to select the cloud vendor that can give you most or all that you need.
Research which vendors offer the tools that you need and have implemented similar architectures that you require. Talk to their customers to learn more about their satisfaction with their solutions. Determine the level of customer service you’ll need and make sure they can provide it.
The selection of your cloud service provider is very important, so take time with this step. But if you’ve done your homework in steps 1-5, this step should be relatively straightforward.
7) Assemble the right talent
Building a big data team might be one of the biggest challenges you can face.
First, there is a pronounced shortage of big data professionals—a problem that won’t be going away anytime soon.
Second, building your own team will require a substantial investment, especially if you don’t have the necessary in-house talent.
But this is a crucial step if your enterprise is determined to adopt a data-driven decision making process. Big data isn’t just about the data and technology; the people side of the equation is just as or more important.
So, where do you start? Looking at your existing team should be one of your first moves.
Do you already have a business analyst who can make the transition to analyzing big data in the cloud? Does your development team have someone who also has the skill set for data software development? People within your organization who already know the business (and preferably, who possess the drive to achieve business goals) could be qualified candidates for your dedicated team.
To complete your big data team, you will still need to hire whatever technical talent you lack in-house. An ideal big data team should be staffed with the following key members:
- Cloud engineers
- Software developers
- Data engineers and architects
- Data scientists
- Business analysts
Once you build your team, you’ll need to make sure they understand their responsibilities not just in their individual roles, but in evangelizing a data-driven movement within your entire organization.
If creating this entire team from scratch is too daunting a task, you can also consider third-party big data managed services. With the right outsourced data team, you can realize ROI faster since you won’t have to spend a lot of time upfront recruiting team members. Once you reach a stable state with your outsourced team, you can continue building your in-house team for the future.
8) Execute your plan
If you’ve done your homework and followed the steps outlined above, it now comes down to putting your plan into action. This requires preparing your data, getting all of your tools in place, and communicating vision, roles, and responsibilities to your data team.
Start small by focusing on your identified objective, but take note of other potential use cases for big data that may be discovered in the process. While the implementation would mainly involve the big data team and other project stakeholders, your organization should encourage a data-driven culture so that any success with your initial big data initiative can be parlayed into future projects.
Conclusion
A well thought-out plan is critical to success of your big data initiative.
It all starts with defining your objectives. Only then can you understand the infrastructure and tools you need, the cloud model to implement, and who you’ll work with.
Then it’s on to building your team and executing.
Spending time on the eight considerations above will put you in a good position to achieve your big data goals.
Like this post? It likes you too. 🙂 Please share it using the share buttons to the left! To get notified of our future Big Data in the Cloud posts, sign up for our email list below.
[thrive_leads id=’26507′]